Download Master PDF Editor 4 For Linux (Free To Use Version) Linux Uprising Blog
I managed to change one of the commands a bit and thought it would be useful to share it here. My requirement was to extract all pages of a pdf file to seperate pdf files, one per page. This can be achieved as follows (The `seq -w 10` gives a sequence from 1 to 10 with leading zeros, replace 10 with the number of pages in the scan.pdf file.
Extract Pages From PDF File With Bitwar PDF Converter
In order to extract a part of a PDF page on a Gnu/Linux machine I use the following command: gs -sDEVICE=pdfwrite -o out.pdf -g2300x2300 input.pdf The -g. I do not want to extract whole pages from the input PDF. The output format should again be PDF. I am not looking for extraction of text or images.
PDF Extract, PDF Télécharger Download

You can use subscript notation with convert(1) to "index" into a PDF: $ convert source.pdf[1] dest.pdf The index value depends on how the PDF exporter numbered the pages. In tests on files here, the numbers seem to be zero-based, so the above example gets you the second page in the document. I've seen examples online where they show letter indexes instead, since apparently the PDF creator.
How to Extract Pages from a PDF Document using Nitro Pro YouTube

pdftk input.pdf cat 1-r2 output output.pdf will drop the final page from input.pdf -- the input should be at least two pages long. To extract just the final page of a PDF in order to test its filesize, run: pdftk input.pdf cat r1 output final_page.pdf Pdftk is available on Linux. Many distros have a binary you can install.
Edit PDF Documents In Linux With PDF Mod (Remove Or Add Pages, Rotate, Reorder PDF Files) Web
Article Source Linux JournalJuly 14, 2009, 9:29 am There are a number of ways to extract a range of pages from a PDF file: there are PDF related toolkits for doing it, or you can use Ghostscript directly. For example, to extract pages 22-36 from a 100-page PDF file using pdftk: $ pdftk A=100p-inputfile.pdf cat […]
Pdfbox split pdf, java extract pages from pdf, YouTube

This CPDF command will split multiple page ranges, but merge them into a single PDF file. cpdf in.pdf 1-3,90-97,112-end -o out.pdf. I need a command that will carry out a similar function to the above command, but output each page range to its own PDF. I've looked for solutions to this problem in the PDFTK and CPDF documentation, but haven't.
How to Extract Pages From a PDF Online YouTube

I have a big PDF and I only need the pages 2-6, 12-33 and 80. How can I separate them and put the files together on a Linux shell without losing quality? When I use. convert *.pdf[1-5,11,32,79] output.pdf I have the pages in one new PDF but with bad quality.
How to extract pages from PDFs 5 quick ways
Sometimes you just want a simple way to extract pages from a PDF. Opening up a GUI is overkill for this task. The Linux command line is here to help with a utility called 'pdftk'. On Debian or Ubuntu based distributions, one can usually install this opening up a new terminal window and typing: sudo apt-get install pdftk -y
How to Extract Pages from PDF YouTube

Just installed poppler a day ago for being able to convert PDF documents to SVG with pdf2svg.Didn't notice that poppler comes with pdfseparate command. Since the accepted answer above (dragging and dropping all PDF pages with preview to desktop) requires me to "click around" and since I like solutions on terminal that work automagically by just a single command line, pdfseparate is exactly.
How to extract pages from a PDF in Linux

And you can extract pages 1 - 5 of input.pdf by using the first-page and last-page flags, -f 1 -l 5, pdfseparate -f 1 -l 5 input.pdf output-page%d.pdf If you want to recombine them into page ranges, for example pages 1-3 in one document and pages 4-5 in another, you can use the companion program, pdfunite, as follows:
How to Extract Documents From PDF Files in Easy Steps?
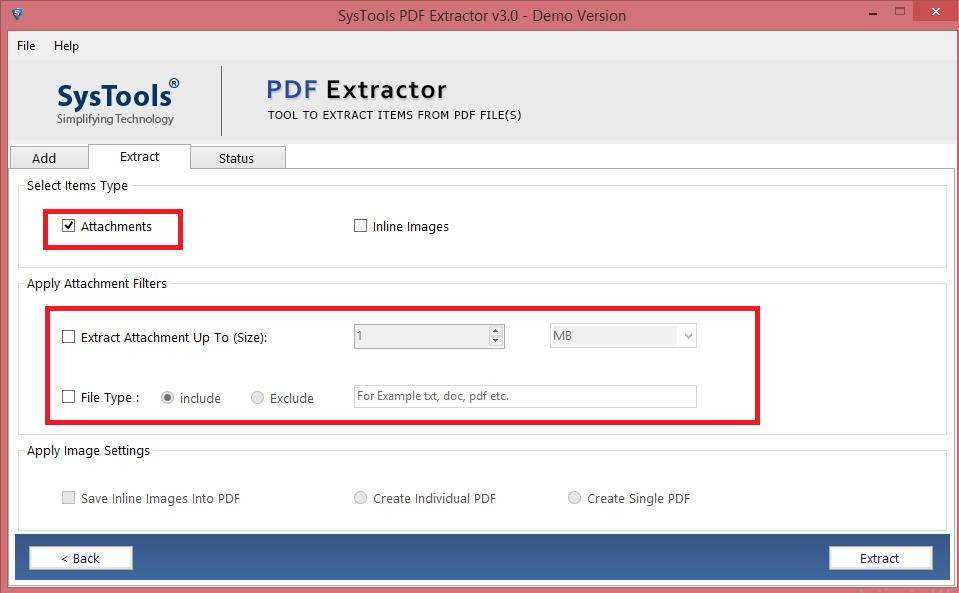
Make the script executable using the chmod +x extract-pages.sh command. Run the script in the terminal using the ./extract-pages.sh command followed by the path to the input PDF file (e.g., ./extract-pages.sh foo.pdf ), specify the desired page range, select the back-end PDF processing tool, and hit OK. Every now and then I need to extract.
Best Software to Extract Images From PDF Documents
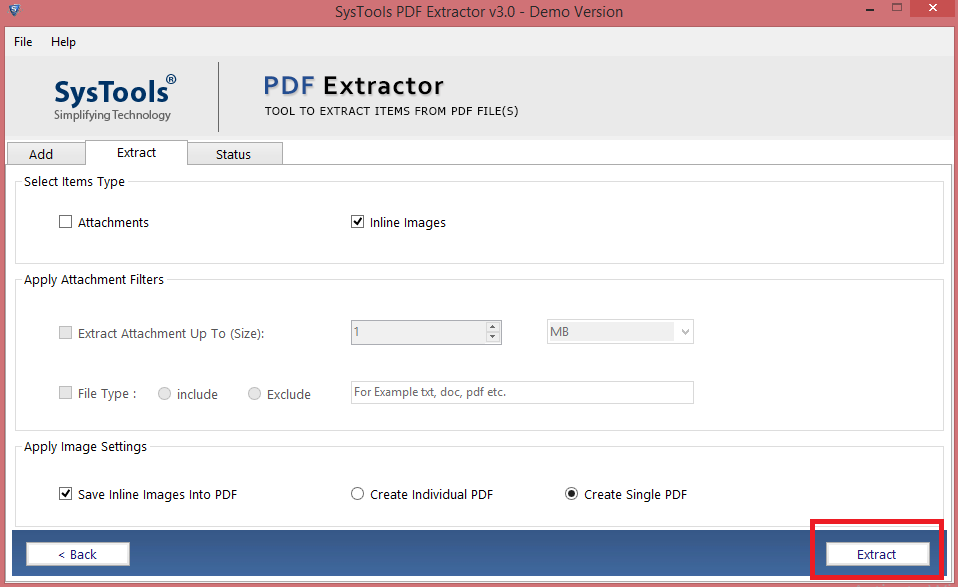
How To Extract Pages from PDF Online for Free. Drop one or more PDFs into the upload box. Select the pages you want to extract from your document (s) Slide the toggle to extract pages into a single PDF or separate PDFs. Click "Finish" or "Extract" to save your new PDF files. Download your file (s) in the format you need.
PDF Complete How to extract pages from a PDF YouTube
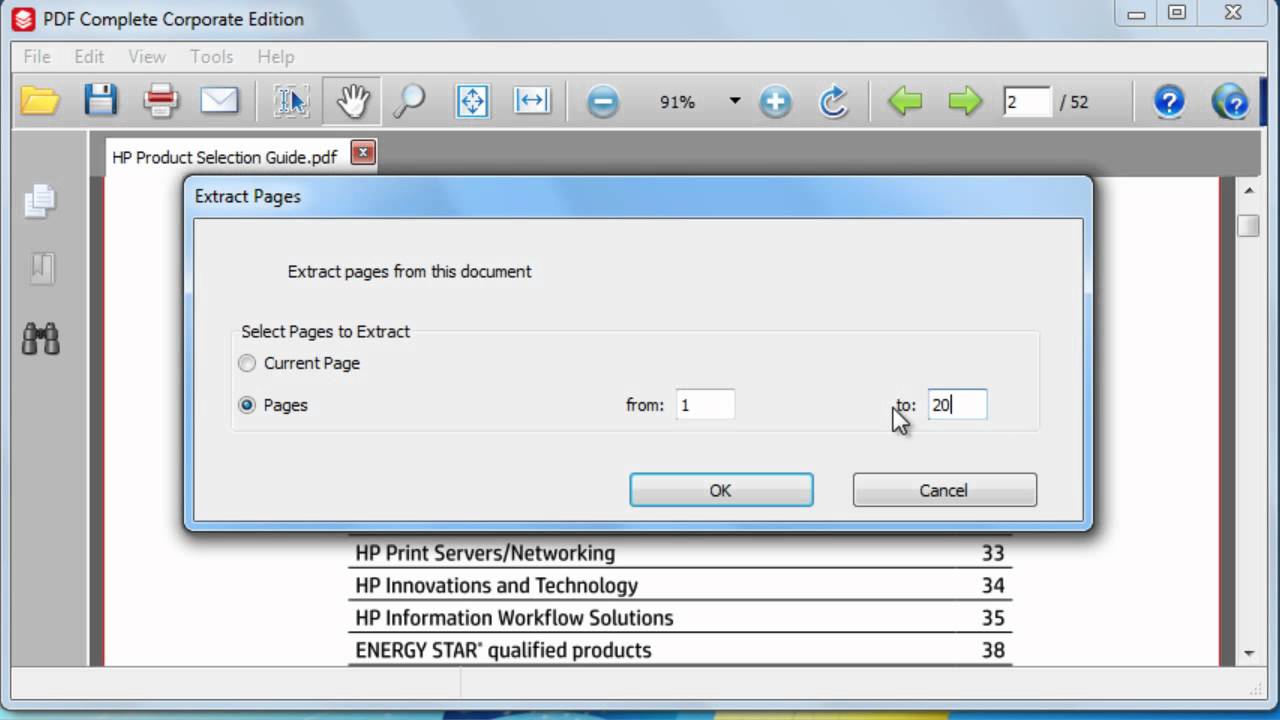
Navigate to the folder where you want to save the cropped pdf, type a name, click the button Format, on the "Select image format type" window select PDF and click the button Select. Back on the "Browse and select a file" window, click the button Save. Before saving, imagemagick will ask to "select page geometry".
11 Best Linux PDF Editors You Can Use in 2023
by Kurt Pfeifle. on July 14, 2009. There are a number of ways to extract a range of pages from a PDF file: there are PDF related toolkits for doing it, or you can use Ghostscript directly. For example, to extract pages 22-36 from a 100-page PDF file using pdftk : $ pdftk A=100p-inputfile.pdf cat A22-36 output outfile_p22-p36.pdf.
How to Extract PNG from PDF with 2 Methods

Extracting Pages from PDFs in Linux: A Comprehensive How-To Guide. Leave a Comment.
How to Extract Pages and Save them as a New PDF Support Kdan Mobile

1. From the quick look at the pdftk homepage. For example if you want to extract 11th page then you can do it like this. pdftk A=full-pdf.pdf cat A11 output outfile_p11.pdf. answered Oct 16, 2014 at 13:54. deimus.